

Základy Support Vector Machines
Úvodný obrázok zdroj: Gerd Altmann, Pixabay
Základy Support Vector Machines, ďalej SVM, boli donedávna najpoužívanejším algoritmom strojového učenia, spomínali sme ho v súvislosti o učení s učiteľom. Ide o klasifikačný algoritmus s cieľom rozdeliť dáta do dvoch tried. V prípade, že sú triedy lineárne separovateľné, hovoríme o lineárnej SVM, v prípade, že nie sú, pojem sa mení na – nelineárna SVM alebo kernelová SVM.
Rozdelenie dát vo vektorovom priestore
Pre lepšiu predstavu uvedieme jednoduchý príklad: Trénovacie dáta sú reprezentované dvojicou príznakov x1, x2 (príznaky sú napr. výška a šírka objektov snímaných kamerou alebo údaje pri chemickom rozbore krvi pri lekárskej diagnostike) a rozdelené do dvoch kategórií. Tieto dáta môžeme znázorniť ako body v dvojrozmernom vektorovom priestore, zobrazené na obrázku nižšie.
Pri lineárne separovateľných dátach môžeme body rozdeliť pomocou priamky (resp. hyperplochy v prípade viacrozmerných dát). Vo všeobecnosti na oddelenie tried môže existovať nekonečne veľa oddeľovacích hyperplôch, avšak pri metóde SVM hľadáme takú hranicu, ktorá vymedzuje po celej dĺžke čo najširšiu vzdialenosť medzi hraničnými bodmi jednotlivých tried, ako je vidno na obrázku nižšie. Pri trénovaní SVM triedy, ktoré sa nachádzajú na vymedzenej hranici, nazývame podporné vektory a šírka hranice reprezentuje kritériálnu funkciu.
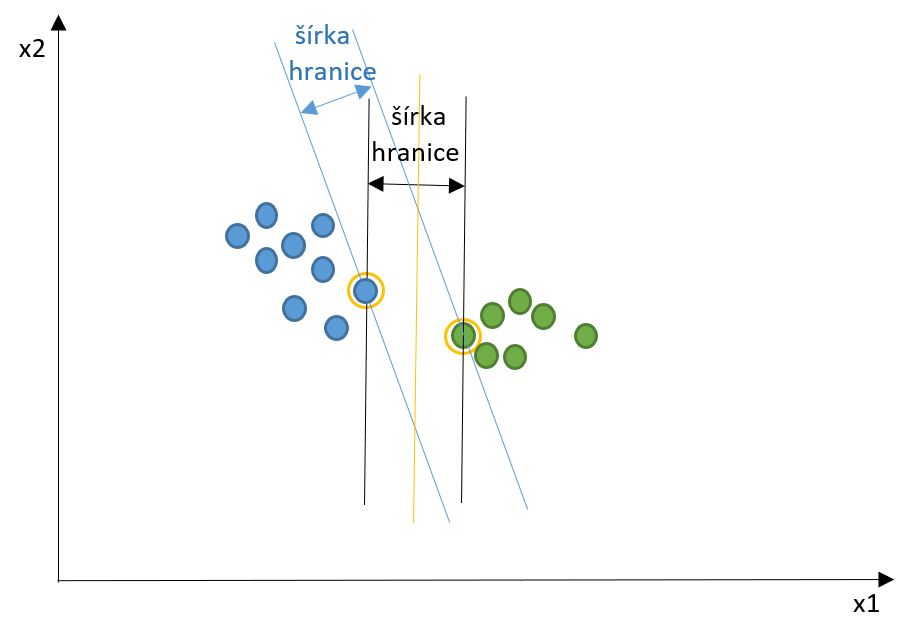
Pre lepšiu predstavu sú jednotlivé triedy dát usporiadané ďalej od seba.
Zdroj: vlastné
Na obrázku je však znázornený ideálny stav, ktorý málokedy nastane. Častejšie sa stáva, že časť dát jednotlivých tried zasahuje do opačnej triedy. V takomto prípade pri trénovaní hľadáme maximum kriteriálnej funkcie, ktorej hodnoty sú penalizované v závislosti od počtu nesprávne klasifikovaných dát.
Kernel
V prípade, keď dáta vo vektorovom priestore nie je možné lineárne separovať, použije sa tzv. kernel trik. Ide o metódu, kde sa pomocou nelineárnej kernelovej funkcie dáta transformujú do nového priestoru s vyššou dimenziou, v ktorom už je možné nájsť deliacu hyperplochu, ako je znázornené na ďalšom obrázku.
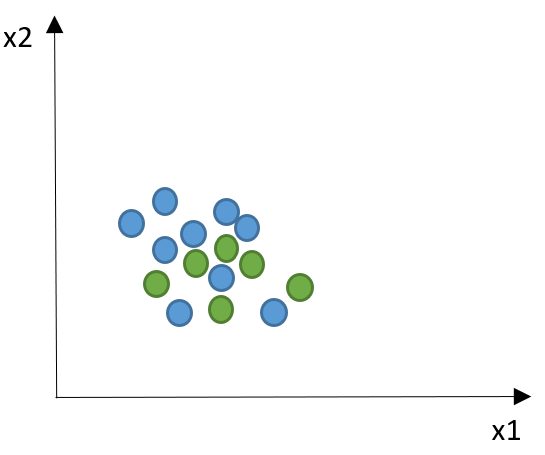
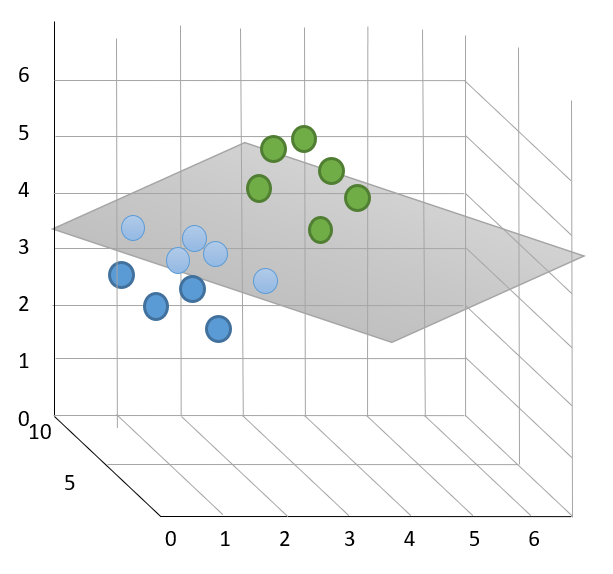
Pred použitím kernel funkcie, po použití.
Zdroj: vlastné
Existuje niekoľko druhov kernelov a výber danej metódy závisí od usporiadania tried.
Medzi základné patria:
– RBF (Gaussian Radial Basis function)
– Polynomiálny kernel
– Sigmoidálny kernel
Ako implementujete tento algoritmus v rámci svojho programovania? SVM knižníc existuje niekoľko, ale napr. LIBSVM vám bude fungovať v .NET, Matlab, JAVA aj Python – tu je používaná aj Scikit Learn, ktorá LIBSVM zahŕňa.
V súčasnosti existuje veľa klasifikačných metód (rozhodovacie stromy, Bayesov klasifikátor, k-najbližších susedov, neurónové siete, …) a tak klasifikáciu či regresiu vykonáte samozrejme aj pomocou nich. Treba len skúšať, ale samozrejme, ak vám napr. pri klasifikácii SVM prinesie uspokojivé výsledky, inú metódu už skúšať nemusíte.
Za informácie k článku ďakujem Ing. Romanovi Jarinovi, PhD. a Ing. Richardovi Orješekovi, PhD.


