

Big Data
Zrejme ste už niekedy začuli pojem Big data. Ide o koncept, ktorý dnes vo veľkej miere napomáha pri vývoji umelej inteligencie. Podľa voľného prekladu z názvu vyplýva, že sú to akési „veľké dáta“. Majú 3 základné charakteristiky – množstvo (Volume), rýchlosť ich tvorby (Velocity) a rôznorodosť (Variety). Čo konkrétne si pod tým však máme predstaviť?
Na internete existuje projekt Every Second, kde si môžete pozrieť, čo sa stane na internete za 1 sekundu. Na nasledujúcom obrázku je príklad toho, čo sa stane na Facebooku za 10 sekúnd:
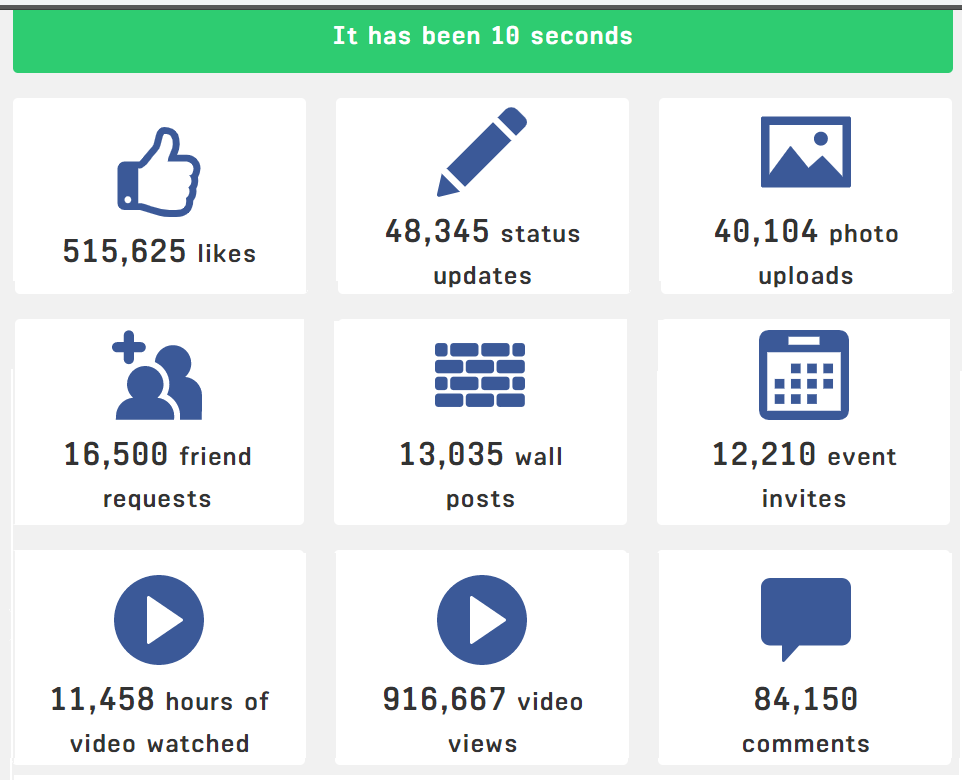
zdroj: EverySecond.io
Len do databáz sociálnej siete Facebook sú denne vložené 4 petabajty dát, medzi nimi okrem iného 350 miliónov fotiek a 100 miliónov hodín videa. Avšak Facebook ani zďaleka nie je jediný „generátor“ veľkých dát. S príchodom ďalšieho konceptu Internet of Things, čo zahŕňa používanie senzorov generujúcich dáta všade kde sa len dá, množstvo nových dát neustále narastá. Predpokladá sa, že v roku 2020 vygeneruje každý jeden človek priemerne 1,7 megabajtov za sekundu, pričom toto číslo bude neustále narastať. Takýmto tempom tak v roku 2025 bude za jeden jediný deň vyprodukovaných až 463 exabajtov dát. Ak sa vám to nezdá tak veľa, tak si pre lepšiu predstavu pozrite nasledujúci obrázok. Pre porovnanie, jedna bežná fotka má približne 3 megabajty, jedna MP3 skladba má zhruba 5 megabajtov.

zdroj: vlastné
Čo s takým množstvom dát?
A ak by sme všetky tieto dáta chceli spracovať použitím tradičných techník na spracovanie dát, nebude to nijako možné. Problém je aj so samotným uchovávaním dát, pretože doteraz používané relačné databázy už nie sú postačujúce. Riešenie ponúkajú Cloudové služby. Ide o množstvo výkonných počítačov spojených počítačovou sieťou, ktoré sa navonok javia ako jeden veľmi výkonný počítač. Poskytujú 3 hlavné služby – Infraštruktúra ako služba (IaaS), Platforma ako služba (PaaS) a Softvér ako služba (SaaS). Pre použitie výpočtov v cloude nám potom stačí len počítačová sieť a webový prehliadač. Všetky služby sa nastavia používateľovi na mieru, a tak používa a platí len za to, čo skutočne spotrebuje.
Práve použitie Cloudu a ne-relelačných tzv. NoSQL databáz (OrientDB, MongoDB) mení spôsob ako sú ukladané a spracovávané dáta. Tým by sme teda vyriešili ako ukladať dáta a kde ich spracovať, stále však zostáva otázka AKO ich spracovať. Riešením tejto otázky sa zaoberá „veda o dátach“ (Data science).
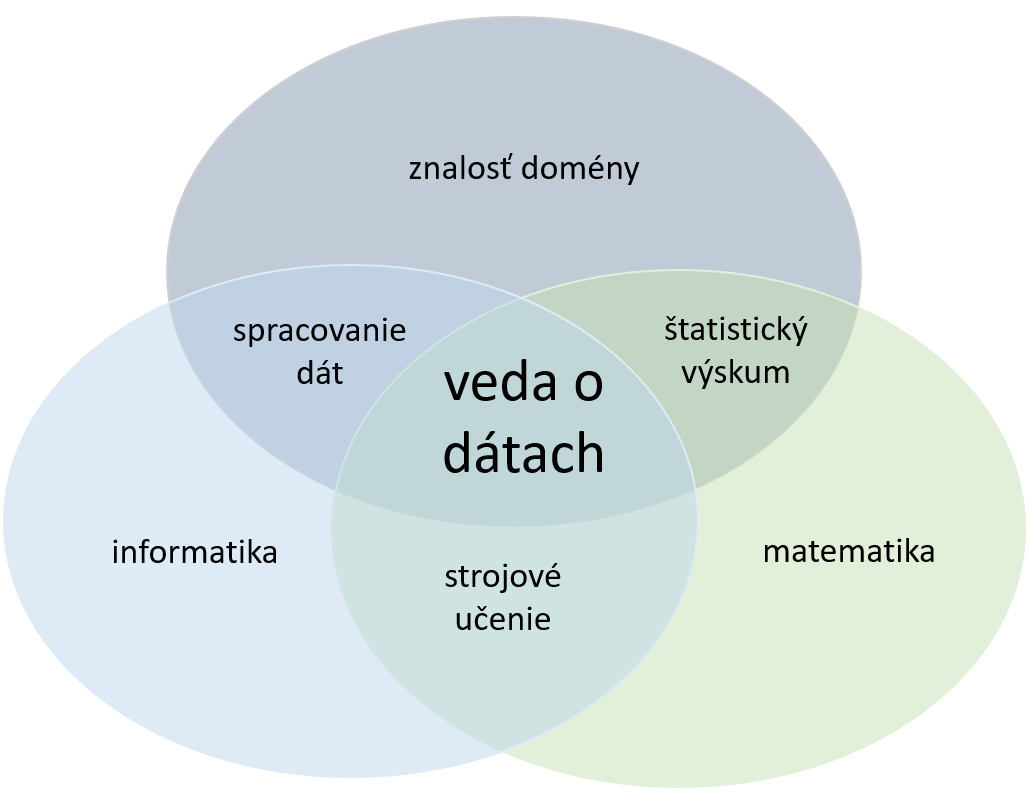
zdroj: houseofbots, upravené
Dolovanie dát – Data minig
Úlohou dátových vedcov a dátových analytikov je skúmanie a extrahovanie informácií a znalostí z dát. To v sebe zahŕňa odfiltrovanie nepodstatných či chybných dát, analýzu a následné zhodnotenie a vyvodenie záverov. Tento proces sa nazýva dolovanie dát (Data mining). Ako môžeme vidieť na predošlom obrázku, spája sa tu matematika, informatika a znalosť domény, z ktorej dáta pochádzajú. Keďže dát je obrovské množstvo, jednou z hlavných úloh dátovej vedy je tento proces čo najviac automatizovať. Tu prichádzajú na rad pokročilé štatistické metódy a strojové učenie, o ktorom sa môžete dozvedieť viac v článku Algoritmy strojového učenia.
Na záver otázka: Ako nám Big data môžu pomôcť pri tvorbe umelej inteligencie? Ako príklad uvedieme Facebook. Keď ste naň v minulosti nahrali fotku, vyzval vás, aby ste na nej označili ľudí, ktorí sa na nej nachádzajú. Tým, že ste tak urobili, prispeli ste ku vytvoreniu databázy tvárí, na základe ktorej teraz môžeme naučiť umelú inteligenciu identifikovať ľudí.
Zdroje:
https://www.oracle.com/big-data/guide/what-is-big-data.html
https://addepto.com/process-huge-data-sets-using-big-data-technology/
https://www.guru99.com/what-is-big-data.html
https://www.visualcapitalist.com/how-much-data-is-generated-each-day/



tolko chyb v jednom clanku…
a) bajty su nasobky 1024 a nie 1000, ako ine jednotky SI (kilobajt = 1024b, megabajt 1048576 bajtov, …)
b) ked je to uvedena „tabulka“, preco je to obrazok?
c) odkedy na SVK formatujeme cisla oddelovacou ciarkou namiesto medzerou?
d) MariaDB je SQL databaza!! je to fork MySQL.
Ďakujeme za komentár, opravíme. Čo sa týka bodu a), áno, ale nie je chybou použiť čisto pre lepšiu názornosť násobky 1000 (10^3). A pokiaľ použijete násobky 1024 (2^10), tak sa jedná o KIBIbajt, MEBIbajt atď.
Pingback: Programovacie jazyky pre vývoj umelej inteligencie II. - Umelá Inteligencia.sk