

Ako postupovať pri tvorbe AI aplikácií
Úvodný obrázok zdroj: John Conde, Pixabay
V tomto článku si povieme pár tipov, ako postupovať pri vývoji slabej umelej inteligencie, resp. strojového učenia. Budeme hovoriť konkrétne o neurónových sieťach a ich aplikáciách v počítačovom videní, avšak veľmi podobný postup bude aplikovateľný aj pri iných algoritmoch a úlohách.
Je potrebné / možné použiť strojové učenie?
Pred tým než začneme, pozrime sa najskôr na problém, ktorý chceme vyriešiť. Musíme hneď automaticky siahať po strojovom učení? Ak áno, je vôbec možné tento problém vyriešiť s jeho použitím? Na jednej strane môžeme mať problém, ktorý vyriešime jednoduchou segmentáciou obrazu, napríklad na základe farieb, teda bez strojového učenia. Na druhej strane zas môže stáť úloha, ktorú nevyrieši ani ten najzložitejší algoritmus, pretože to jednoducho nejde. Existuje jednoduchá heuristika: „Ak dokáže človek voľným okom vyriešiť daný problém za menej ako 1 sekundu, vtedy je naň možné aplikovať strojové učenie“. Nie je na mieste tu čakať zázraky, proste a jasne, ak to jednoznačne nevidí človek, nebude to pravdepodobne „vidieť“ ani počítač. Ak je však úloha vhodná pre strojové učenie, a máme dostatok dát pre jej vyriešenie, ideme na to.

zdroj: Comfreak, Pixabay
Začíname
V prvom kroku je potrebné určiť, ktorú techniku potrebujeme použiť na vyriešenie nášho problému. Potrebujem identifikovať a klasifikovať objekt na vstupnom obrázku, alebo len zistiť jeho prítomnosť, potrebujem nájsť jeho umiestnenie v rámci obrazu alebo ho potrebujem aj presne vysegmentovať? Tu Vám môže byť nápomocná naša séria článkov o počítačovom videní. Po správnom rozhodnutí nasleduje výber vhodnej architektúry neurónovej siete. Existujú desiatky hotových a otestovaných architektúr pre rôzne úlohy. Väčšina z nich je implementovaná vo viacerých frameworkoch a programovacích jazykoch s voľne dostupnými zdrojovými kódmi, a dokonca aj s predtrénovanými modelmi. Záleží len od toho, akú úlohu potrebujete riešiť. Ak chcete riešiť klasifikáciu objektov, môžete použiť známe architektúry ako AlexNet, GoogLeNet, VGG-16, VGG-19, ResNet-50, Inception-v4 či mnoho ďalších. V prípade že riešite detekciu objektov, máte k dispozícií napríklad Faster R-CNN, SSD, YOLO, atď. Na výber sú teda jednoduché aj veľmi komplexné architektúry. Pri výbere potom záleží, aký výpočtový výkon máte k dispozícii, koľko času môžete obetovať pre vyhodnotenie jedného vstupu a akú presnosť požadujete. Tu treba teda spraviť rozumný kompromis cena – kvalita. Buď si môžete sami vybrať, vyskúšať a porovnať vybrané architektúry, alebo si na webe vyhľadať rôzne prehľadové porovnania a na základe toho sa rozhodnúť.
Nemusíte však použiť iba existujúcu architektúru. Neraz sa ukáže ako najlepšie navrhnúť si vlastné riešenie a vlastné experimenty a vytvoriť si na mieru presne to, čo potrebujete. Ak ste však v oblasti neurónových sietí začiatočník a nemáte s návrhom architektúry veľa skúseností, alebo len potrebujete inšpiráciu, nebude je na škodu začať štúdiom známych overených architektúr. Neexistujú totiž žiadne exaktné pravidlá, ako zostaviť neurónovú sieť, je to do veľkej miery experimentálna činnosť.
Trénovanie modelu
Keď sa Vám konečne podarí zvoliť vhodnú architektúru, prichádza na rad trénovanie. Ako už bolo spomenuté, vybrané existujúce voľne dostupné implementácie často ponúkajú už natrénované modely. Tieto architektúry a modely bývajú často dobre zvalidované a otestované, a v niektorých špecifických úlohách pre Vás môže byť postačujúci už aj takýto model bez potreby ďalšieho trénovania z Vašej strany. Prípadne ho môžete použiť takýto predtrénovaný model na dotrénovanie na Vašich dátach (tzv. transfer learning).
A konečne sa dostávame k dátam – zlatému grálu strojového učenia. Výsledky algoritmu strojového učenia sú totiž priamo úmerné kvalite dát, ktoré sme mu poskytli počas jeho tréningu. Platí tu obligátne „Čím viac, tým lepšie“. Základom je teda mať dostatok kvalitných dát. Ak sa Vám zdá, že ich dostatok nemáte, môžete sa obzrieť po množstve voľne dostupných datasetov na webe. Takisto možno vykonať tzv. augumentáciu dát, čo je veľmi často používaná technika na rozšírenie trénovacieho datasetu. Jednoduchými operáciami ako je rotácia, posunutie, priblíženie a oddialenie obrazu, môžete výrazne rozšíriť objem svojich trénovacích dát a napomôcť tak robustnosti výsledkov trénovaného algoritmu. Okrem množstva dát je však dôležitá aj ich rôznorodosť a vyváženosť, tak aby obsiahli čo najväčšie množstvo možných reálnych stavov a situácií. V prípade klasifikácie dát do tried je potrebné, aby mala každá trieda v rámci datasetu zhruba rovnaké zastúpenie.
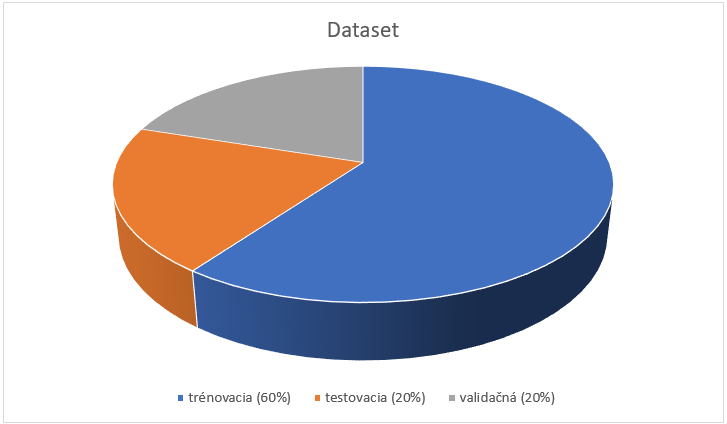
Po zhromaždení dostatočného počtu dát prichádza krok, kde si ich rozdelíme do nasledujúcich množín v odporúčaných pomeroch:
- trénovacia (60%)
- testovacia (20%)
- validačná (20%) – nepovinná
zdroj: vlastné
Trénovacia množina ako základ
Najdôležitejšou je trénovacia množina, ktorá je vstupom do trénovacieho cyklu. Práve z dát trénovacej množiny sa algoritmus učí príznaky potrebné pre správnu detekciu či klasifikáciu. Výstupom trénovania je model, ktorý následne vieme použiť sa vyhodnotenie nových dát. Avšak môže sa stať, že model perfektne natrénujeme na trénovacej množine, ale keď sa ho budeme potom snažiť použiť v praxi, zistíme, že jeho výsledky za veľa nestoja. Tento stav sa nazýva pretrénovanie, tzv. overfitting, a nastáva vtedy, keď model nie je dostatočne generalizovaný. Pretože naším cieľom nie je to, aby algoritmus vedel bezchybne vyhodnotiť všetky trénovacie dáta, ale aby vedel neskôr správne vyhodnotiť aj iné podobné dáta, ktoré pri tréningu „nevidel“. Z tohto dôvodu bola zavedená testovacia množina. Princíp je jednoduchý, model natrénujeme a vyhodnotíme na trénovacej množine, a následne ho ešte vyhodnotíme na testovacej množine. Potom vieme ľahko porovnať, ako sa algoritmu darí na známych aj neznámych dátach.
Ale čo ešte tá validačná množina, označená ako nepovinná? Validačná množina slúži na testovanie parametrov modelu, napríklad hyperparametrov architektúry neurónovej siete v prípade, že navrhujete vlastnú sieť. Použitie je prosté. Navrhnete sieť, natrénujete ju na trénovacej množine a otestujete na validačnej. Potom sieť mierne upravíte (zmeníte počet neurónov vo vrstve, zmeníte aktivačnú funkciu), trénovací proces zopakujete a porovnáte tieto hodnoty, čím zistíte či to bola zmena k lepšiemu alebo horšiemu. Ale ako bolo povedané, validačnú množinu vytvárať vôbec nemusíte, napríklad ak používate už overenú architektúru, v tom prípade rozdeľujete Váš vstupný dataset na trénovaciu a testovaciu množinu v pomere 80% a 20%.
Ako dlho trénovať?
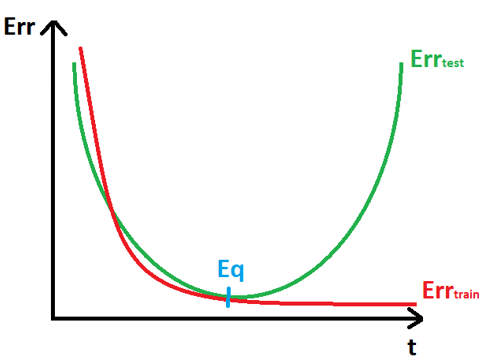
Pokiaľ by sme si tieto výsledky trénovania značili do tabuľky, vykreslený graf by vyzeral pravdepodobne nejak takto:
zdroj: vlastné
Na grafe vyššie je znázornená chybovosť, ktorú algoritmus vykazuje pri vyhodnotení na vybranej dátovej množine, v danom časovom okamihu počas trénovania. Červenou je zobrazená chybovosť dosiahnutá na trénovacej množine, zelenou na testovacej. Na začiatku trénovania bude chybovosť pravdepodobne na oboch množinách veľmi vysoká, s pribúdajúcimi trénovacími iteráciami však začne aj rýchlo klesať. V istom bode, v grafe označenom ako Eq, však testovacia chyba začne stúpať. Prečo? Pretože od tohto bodu nastáva spomenuté pretrénovanie. Sieť prestáva byť generalizovaná a učí sa nepodstatné detaily z trénovacích dát, aby čo najviac znížila trénovaciu chybu, ale na druhej strane začne strácať podstatné naučené príznaky, začne chybne vyhodnocovať testovacie dáta, a teda testovacia chyba začne narastať. Zjednodušené povedané, začne byť tak dobre naučená na trénovacích dátach, že nebude vedieť vyhodnotiť žiadne iné dáta. Preto je práve bod Eq hranicou, keby je potrebné ukončiť proces trénovania. Nie vždy to však hneď ide tak hladko, ako by sme chceli. Môže sa stať, že po začatí trénovania začne trénovacia chyba namiesto klesania rásť, prípadne oscilovať. Spravidla je to však spôsobené zlým nastavením trénovacích parametrov (príliš veľký learning rate, nevhodné momentum), prípadne chybou v dátach (chybné označenie dát, nevyváženosť dát).
Slovo na záver
V tomto momente máte v rukách hotový natrénovaný model, ktorý hneď môžete zaviesť do praxe. Avšak pochopiteľne to nemusí všetko vyjsť na prvý raz. Môžete naraziť na množstvo problémov, buď čo sa týka dát, alebo samotného návrhu riešenia. Oblasť strojového učenia je totiž experimentálna činnosť, ktorá stále skrýva mnoho nečakaných a nepredvídateľných nástrah. Akonáhle ich však dokážete poraziť, máte v rukách veľmi užitočný a mocný nástroj.


