

Dokáže umelá inteligencia predpovedať úspešnosť piesne?
Úvodný obrázok zdroj: Simone_ph, Pixabay – upravené
Už sme písali o tom, či dokáže umelá inteligencia predpovedať IQ dieťaťa ešte predtým než sa vôbec narodí, ako vie predikovať úbytok množstva ľadu alebo vopred určiť vlastnosti stavebných materiálov . Ale poradila by si aj s takouto možno netradičnou, ale o to náročnejšou úlohou?
Potenciál
Hudobný priemysel sa dnes najmä vďaka streamovacím službám ako Spotify či Youtube teší obrovskej obľube a točia sa v ňom naozaj slušné peniaze. Aj za minulý rok, ktorý bol silno poznačený pandémiou a nemohli sa preto konať festivaly ani turné, boli príjmy niektorých umelcov v miliónoch. Počas lockdownu však mnohí umelci využili čas na to, aby tvorili nové veci, ale trafiť sa ľuďom na strunu a napísať niečo komerčne úspešné je dnes naozaj enormne náročné. Nebolo by teda super mať nástroj, ktorý povie, či bude mať daná pieseň úspech, ešte skôr ako sa dostane von?

zdroj:
Ako začať?
Tento zaujímavý problém je už dlhší čas oblasťou výskumu a venuje sa mu množstvo publikácií, my sa bližšie pozrieme na prácu výskumníkov z Kalifornie. V tomto článku sa pokúšajú predpovedať, či piesne budú skórovať v hudobných rebríčkoch na základe rôznych príznakov jednotlivých skladieb. Čo si ale máme predstaviť pod týmito príznakmi? Všetko čo vám napadne – text piesne, trvanie, tempo, žáner, rok vydania, rytmus, hlasitosť, energia či tanečnosť. Dnes už existuje hneď niekoľko datasetov, kde môžete tieto informácie získať o množstve úspešných či menej úspešných skladieb, medzi nimi napríklad Million Song Dataset alebo Echo Nest API. Tieto datasety sú však relatívne chudobné na kompletné dáta, autori uvedeného článku sa preto rozhodli vytvoriť si vlastný dataset s použitím Spotify API, ktoré vie okrem iného poskytnúť práve potrebné príznaky jednotlivých skladieb. Získané metadáta následne skombinovali s dátami z Billboard API, ktoré obsahuje rebríčky najúspešnejších skladieb za posledné desaťročia. Takto sa im podarilo získať dataset o objeme až 1,8 milióna plne anotovaných skladieb.
Použité metódy, vyhodnotenie
S použitím získaného datasetu sa autori pokúsili na túto úlohu natrénovať a vyhodnotiť hneď niekoľko algoritmov strojového učenia. Vybrali si nasledovné 4 – logistickú regresiu, metódu podporných vektorov, neurónové siete a náhodný les. Problém bol postavený ako úloha binárnej klasifikácie, t. j. či sa daná skladba pravdepodobne umiestni v rebríčku najlepších skladieb – stane sa hitom. Po skončení trénovania následne výsledky algoritmov vyhodnotili s použitím troch jednoduchých metrík, nájdete ich v nasledovnej tabuľke:
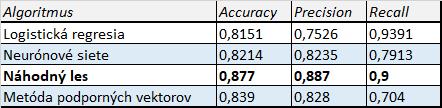
Dosiahnuté výsledky algoritmov
Zdroj: vlastné
Ako môžete vidieť, všetky testované algoritmy dosiahli pomerne vysokú úspešnosť predikcie, a to až na úrovni viac než 80%. Ako najvhodnejšia sa pre tento problém ukázala metóda náhodný les, kde sa na testovacej množine blížila presnosť dokonca k 90%, čo je naozaj slušný výsledok. Ako teda môžeme vidieť, aj s takouto zaujímavou úlohou si umelá inteligencia poradila ľavou zadnou.
Zdroj: University of San Francisco


